
Rainy Days Ahead for Restaurants?
The street I live on in Philadelphia is lined with French restaurants and American bistros. Since these restaurants received the okay to reopen for outdoor dining, this street has been full of diners crowding the hastily set-up tables. All these establishments have basically been turned inside out, their interiors serving solely as facades for the sidewalk now converted into a dining area. Walking down my street, I’ve been wondering about the amount of business these restaurants take in, in the new COVID-19 world. And this ties into another aspect of the current Philly summer life - frequent thunderstorms. Once a minor inconvenience for the city’s restaurants, rain now imposes a harsh limit on their ability to operate. If customers can only eat outside, there’s not going to be much demand on rainy days. But how significant is the weather on consumer traffic to businesses, restaurants and otherwise, and are weather conditions something businesses will have to incorporate into their forecasts while indoor restrictions remain commonplace? While I sadly don’t have access to the daily cash flows of local businesses, there are a number of publicly-available proxies for measuring the day-to-day expenditures at Philly establishments.
First Glance at Business Activity
One excellent source for measuring business activity and consumer habits on a daily basis is Google Mobility Reports. Google has generously provided their collected data from users’ location tracking devices, compiled into daily reports of changes in visits relative to a baseline period to various areas of interest. As Google puts it, “The data shows how visitors to (or time spent in) categorized places change compared to our baseline days. A baseline day represents a normal value for that day of the week. The baseline day is the median value from the 5‑week period Jan 3 – Feb 6, 2020.” So using this measure doesn’t give us an exact picture of the daily level in consumer activity, but it’s close enough for a guy who’s writing a casual post about a random question he had one day. That being said, let’s look at the data for Philly:

We’ve got three categories here: consumer traffic to grocery and pharmaceutical stores, to parks, and to retail and recreation stores. It’s a bit noisy, especially in regards to the parks, which have relatively large high-frequency fluctuations - probably due to the day of the week (week vs. weekend) - and perhaps a first signal of the effect of local weather. This noise is exactly what we want: variation in the time series data that we can exploit to determine if there’s any particular correlation with the weather. For graphing purposes, however, such as viewing the general trends and major differences between the categories, smoothing the data is preferable.

Long-term trends are much more clear here. Parks and retail, which are more optional activities, took bigger hits in April when pandemic regulations were the tightest. Parks have had an especially pronounced rebound since then, which is likely in large part due to improved weather in Philly (this is also likely why traffic was so high in late February, relative to the particularly frigid January-early February period). When the pandemic began winter was still going, and the reopening of public spaces coincided with the warmer spring and summer weather. On the other hand, traffic to grocery & pharmaceutical stores, sellers of much more essential goods, remained relatively stable, though still below pre-pandemic levels. Anyways, we’ll be using the data in it’s raw, noise-filled form for analysis from here on out.
Another useful and graciously shared dataset is OpenTable’s data on seated diners at restaurants. This data is also relative, this time showing the percent change relative to the same day a year ago (year-over-year change).
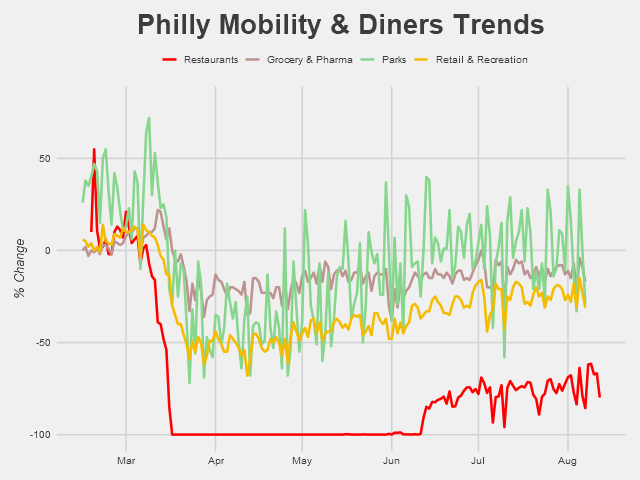
The damaging impact of the pandemic on restaurants is apparent. Even with the reopenings and relatively low COVID-19 case counts in Philly, visits to restaurants remain way below baseline level. We’re also seeing a fair amount of variation since the mid-June reopenings, with several pronounced dips occurring semi-regularly. One of those dips is due to the July 4th holiday - but could the other ones be responses to rainy days?
Identifying Rainy Days
Now that we’ve got our trends, the next step is actually examining the weather. Using the National Weather Service’s data, we can identify exactly which days in Philadelphia it rained.

Days shaded in blue are days when rain was recorded in Philadelphia; that’s a lot of rainy days. I’m also excluding here the days that have a “trace” amount of rain - .01 inches or less. Lining up the dips with those rainy days, it looks like some dips line up with the rain, some don’t. But overall it’s hard to tell, and besides that, some simple chart comparisons aren’t enough to make anything besides educated guesses. For real insight, we’re going to need to do some actual economic analysis.
A Drop of Analysis
There are, of course, a number of methods available to determine if rain had a significant effect on the traffic to restaurants (we’ll be focusing on just restaurants from here on out). One simple and direct method is to run a linear regression of diner traffic on a dummy variable for rainy days. Doing this for our data beginning mid-June (when reopenings began) provides the following results:
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -74.4886 0.9363 -79.56 < 2e-16 ***raindays$rain_flag -6.4358 1.7826 -3.61 0.000654 ***The above coefficients table tells us that on sunny days, diner traffic averaged -74.5% relative to the same day a year ago, and on rainy days traffic dropped to about -81%. So rain was responsible for a 6.4% drop in business to restaurants and (as indicated by the low p-value) this difference was certainly significant.
Compare these results to the same regression run on the data for February to mid-March, before the pandemic came to Philly:
Coefficients: Estimate Std. Error t value Pr(>|t|)(Intercept) 0.8421 4.7802 0.176 0.862raindays$rain_flag -2.1278 9.2127 -0.231 0.819Before restaurants shifted to outdoor-seating only, the effect of rainy days was only a 2.1% drop in diner traffic - not a large enough difference from the sunny days to be considered significant (for this time period, diner traffic averaged 0.8% higher than the same period a year ago).
One other way we can test for significance in the difference between rainy and sunny days is with a difference of means test. Specifically of use, in our case, a Wilcoxon test that does not assume anything about the underlying distribution of our sample. Difference-of-means tests, as the name implies, determines whether the averages of two groups are significantly different from each other. Running two of these - a two-sample t-test and a Wilcoxon test - on our post-pandemic data results in:
t-Test
t = 2.4544, df = 15, p-value = 0.02681alternative hypothesis: true difference in means is not equal to 0Wilcoxon Test
W = 171.5, p-value = 0.004328alternative hypothesis: true location shift is not equal to 0Both these tests have p-values below .05, indicating that the difference in average diner traffic between rainy days and sunny days is significant. As before, we can run the test on the data pre-shutdowns to see if this is pattern is novel to the reopening period.
t-Test
t = 4.7013, df = 6, p-value = 0.003322alternative hypothesis: true difference in means is not equal to 0Wilcoxon Test
W = 69.5, p-value = 0.885alternative hypothesis: true location shift is not equal to 0While the t-test actually says there is a significant difference here as well, the Wilcoxon test (with a p-value of 0.885) strongly rejects any difference between the means. Given that our data is very likely not following a normal distribution (as assumed by the t-test), we’ll hold the results of the Wilcoxon test in higher esteem.
Conclusions
The above results together support the notion that the shift in dining policy due to the pandemic has created a new dynamic - one where the possibility of rain is now a notable detriment to restaurants’ success. Moving toward the colder seasons, it’ll be interesting to see how inclement weather may continue to have an outsized impact on restaurants relative to pre-pandemic effects. Sitting under an umbrella in a summer rain with 80-degree weather is one thing, but sitting outside when it’s snowing and/or below 30 degrees is another. If COVID-19 remains through early 2021, we may see eating establishments (outside of the warm southwest) in the US struggle with the additional burden of effective closures or diminished traffic on days where diners aren’t willing to brave the weather for a bite to eat.
One last note is not to take the results of the above tests too seriously. First off, the sample sizes are way too small, and the tests I ran are very surface level. Including more explanatory variables in the regression would likely change the results and are one of many additional steps that could be taken to lend results greater legitimacy. While my results may provide a hint of significance, they are only small dips into the real type of analysis that needs to be done to properly establish causation. However, I also don’t think it’s too much of a stretch to conclude that bad weather might prevent a significant portion of people from going out to eat when their only option is to eat outside - in that bad weather. Time, and local weather conditions, well show if this turns out to be true.
Final Notes
Thank you to Google, OpenTable, and the National Weather Service for making the data used in this post publicly available.
Charts seen in this post were made in R using the ggplot2, tidyverse, readxl, and Cairo packages.
A very useful resource for determining which difference of means tests to run and how to do so in R was https://uc-r.github.io/t_test.
An always-helpful resource for picking complementary colors in charts (used in many of my previous posts as well) was https://coolors.co/. Thank you to the folks at Coolors, as well as my friend Vanessa Wong, for advice on creating charts pleasing to the eye.
If you have questions or constructive feedback, feel free to email me at troded24@gmail.com, submit an inquiry on this website, or leave a comment on this post! Thanks for reading.

Charting the Effects of a Pandemic with High-Frequency Data
The singular topic on every person’s mind these dates is the coronavirus epidemic, and rightly so. The virus has shaped or influenced nearly every aspect of our lives, from work to socializing to our very lives themselves. In tandem with this, there has been a flood of attempts to chart the course of the outbreak in the US and the corresponding recession following in its wake. Such forecasting, which is always complex, is made increasingly difficult for a number of reasons. Obviously, the virus itself is not yet entirely understood and our knowledge of its underlying characteristics that determine its spread is still under development. The situation in most affected nations is rapidly changing, with new numbers being watched closely for every day.
Anyone actively following the news has taken notice of two fundamental aspects in the reporting: a desire to understand where we’re headed, and a distinct lack of data to facilitate such understanding. In this post, I will focus on the unfolding recessionary aspect of the pandemic, where the available data is appreciably better (and more in my realm of knowledge). However, here too exist many obstacles preventing accurate forecasting from being done. Again, to those who have followed the news persistently, you may have noticed that forecasts of various economic measures - GDP and unemployment in particular - have a great variance.
Economic data is often “lagged” from it’s release. In other words, data on macro measures for the current month won’t be released, or not very accurately so, until weeks or even months following the time period covered. This is a symptom of trying to measure such large and complex processes such as GDP growth and unemployment, which requires a significant number of sources and compiling effort, not to mention successive cleaning and adjustments for published figures. The upshot here being that forecasting the severity of the crisis we now face is made further difficult by the lack of accurate economic data actually reflecting the current situation. It is much to ask for a prediction of Q2 GDP growth when we don’t even as of yet have a solid estimation of Q1 GDP growth.
However, the proliferation of data and its public availability offers an alternative to waiting around for such lagged data to be released. Data has become increasingly opened to the public by businesses, cities, and independent researchers. A key feature of much of this data is it’s high-frequency structure: much of the data these entities collect and share is available up to the daily level. Through the good will of these data sources, we can track the ripples of COVID-19 through our economy in the most up-to-date way possible - treating our high-frequency data as “coincident” indicators. Doing so allows us to more quickly and accurately understand the unfolding situation and better forecast (to the near-future, at least) where we might be headed. Such knowledge can then help inform rapid policy decisions and short-term expectations.
One caveat to this data, particularly the ones used in this article, is that they are only proxies for our macro statistics of interest. High-frequency data may provide more attention to “noise” and miss larger trends. Or, as is often the case with data released by individual firms, it will only be focused on a certain region or industry that makes up one small part of the broad macroeconomy. Still, when analyzed cautiously and combined with lower frequency data, using such sources can aid in quickly forming needed forecasts or at least provide a hint of what’s to come. So keep in mind that with high-frequency data like this there is a high degree of error and volatility. Using this data can help provide some useful information on current conditions, but to truly grasp the bigger picture accurately will take months or even years - likely not until this entire outbreak is controlled.
Hourly Workers, Daily Data
There has been much discussion in the news surrounding the unemployment numbers - certainly a key measure, but a very lagging index as well. National unemployment statistics come out on a weekly basis at best, and even then the week they represent is several weeks behind the current one. More concise reports come out on a monthly frequency. A different statistic that can provide insight on unemployment at a much higher frequency is provided by Homebase - a scheduling and time tracking software. This data was shared on Greg Mankiw’s blog (which is how I came across it), so thank you to him and to Homebase for sharing this fascinating data. Using Homebase data, we can gain insights into employment for hourly workers - consisting of employment in the restaurant, food & beverage, retail and services industries - and how that has changed on a day-to-day basis.

Note: Data covers March 2, 2020 - March 31, 2020.
The above chart shows the day by day change in hours worked, compared to a base period in January 2020. Right around March 9th the average hours began dipping dramatically, bottoming out at around -60% on March 22nd. The steep drop begins almost immediately after the White House declared a national emergency on March 13th - prompting states and businesses to ramp up social distancing measures. Although the data here is just a sample of one type of worker from businesses covered by Homebase, it reveals just how hard hourly workers - who constitute a significant portion of the service industry - have been hit by business closures. It is almost certain that the full effect of this work reduction has not been realized throughout the economy yet. Likely we will see a further rise in the overall unemployment rate for much longer, as both the economic freeze takes hold and the unemployment data itself catches up to reality. The good news, perhaps, is that the reduction seems to have stabilized at this level since March 22nd.

Note: Data covers March 2, 2020 - March 31, 2020.
Another perspective, again using Homebase data, focuses on the number of hourly employees working compared to a base period covering January 2020. Rather than looking at the change among hours worked by employees, we can compare how many employees are still working at all. A slightly different perspective on the same sample, but we see very similar results. By the end of March we have a 60% decrease in the number of employees working compared to a similar weekday in January, a huge reduction in just two short months. The trend for this series closely tracks the reduction in hours worked by those remaining on the job.
In fact, if we overlay the two series, we see that they’ve followed almost an identical pattern:

So we have a major drop in both hours worked and number of people working among the hourly employees in the Homebase dataset - a drop not yet fully captured in the nation-wide macro figures.
Restaurants and OpenTable Data
Another daily tracker, this time made available by OpenTable, is the number of customers at restaurants. This “diner index” (including online reservations, phone reservations, and walk-ins) is a clear indicator for the hardest hit businesses, and it shows just how bad the reality is for restaurants. Instead of looking at how businesses are affected through the labor market, we’re now looking at the economic trend from the consumer’s perspective.

On March 1st, coronavirus had not yet impacted diners in any meaningful manner. Compared to the same day a year before (year-over-year, or YoY), most restaurants were serving as many, or slightly more, customers. On average, the number of seated diners was about 8% higher across all states than the previous year. Kansas and Missouri establishments were thriving, up 69% and 72% YoY, but I would attribute this to small sample sizes in the OpenTable data for those states rather than hungrier than usual Midwesterners. Still, the point is we see what you would expect for an economy chugging along with no immediate known threats - average to good performance.

Just two weeks later, we see a very different picture. Average restaurant traffic is down nearly 50% across all states, ranging from down 31% in South Carolina to down 67% in Maryland. At this point business closures had begun in some states - particularly the most affected such as California and Washington (-55% and -57%) - and many chose to avoid eating out as the virus was spreading rapidly.

By the end of March, the change in seated diners hit rock bottom - down 100% in nearly every single state. By this point most states had mandatory shutdowns, and the few restaurants remaining open offer only delivery/take-out options - not measured in this data. Although not shown in the maps above, most states were already down 100% by March 23rd, just 3 weeks from a normal day business-wise. It’s fascinating to see just how quickly the situation was evolving, and how even the most financially-prepared businesses can be thrown into chaos and ruin before they even realize what hit them.
Stock Market Blues and Clues
A well-known high-frequency measure of the state of the economy is the stock market. Stock prices are updated every second and using daily closing prices can, at the very least, provide us with knowledge of investor sentiment for the current path of the economy. Further, markets are forward-looking and prices theoretically reflect expectations of the future. In this manner we can look at the market - through the S&P 500 Index - as a leading indicator, hinting at what may be to come. In reality, stock prices and expectations are much more complicated than that and are a reflection of a wide range of factors, some not so directly tied to the economic situation. Federal Reserve injections, information from other countries, and company- and sector-specific idiosyncrasies all play important roles in determining market movement. Still, when a global and structural shock occurs like a pandemic, markets and event timelines tend to be closely correlated.

I decided to focus on three broad indices: the S&P 500, meant to reflect the entire market, AWAY, an ETF consisting of travel and tourism companies, and JETS, an ETF consisting of airlines. We could consider the S&P 500 as a representative for the general economy, and our two ETFs as representatives for some of the most affected industries due to COVID-19. This is clearly reflected in their 2020 YTD performance, as AWAY and JETS have lost about half their value since January 2, 2020 - about 20% worse than the S&P 500 index. These latter indices reflect the worst-case scenario: a result of an industry’s entire revenue stream being abruptly shut off.

How do market indicators compare to our previously looked at data? Actually, pretty similar! In the above chart, I added the Homebase data on change in hourly employees hours worked (the dashed purple line) and the OpenTable diner index data (for the entire US, the dashed blue line) to our market indices chart. The stock market appears to have anticipated the decline in the consumer and labor markets by several weeks, the actual business figures only catching up to their stock prices in mid-March.
Keep on the Lookout
Maintaining an awareness of high-frequency data series such as these can provide an indication of when we hit bottom or when things are looking up. By the time that unemployment and GDP statistics capture a more complete economic picture of this crisis, the worst may have already passed. Or maybe not. Even if emergency declarations become unnecessary or current “economic coma” policies are removed, it may take some time for the economy to start its engine again. Stock market indices appear to have begun picking up in the last week or so, but this doesn’t exactly imply quick economic recovery - restaurants and the job market remain at their lows and social distancing regulations propose to stay in place for the foreseeable future. When the recovery may begin and how tenacious the bounce back will be remains anyone’s guess.
Final Comments
This post was written in the first week of April 2020, and as such the views of this author reflect information available at that time. Data used in this post has already been further updated and elongated at the time of publication.
Homebase dataset is generously made available, and regularly updated, here: https://docs.google.com/spreadsheets/d/e/2PACX-1vTf0Ce37p3B0Qy-5BZPh1p9-WwEekPOxVdpMsumy6JFeCIt9EO6ZxbGNpnNxjdf9Mr9USeIMqjq9YU0/pubhtml#
OpenTable data is available on their website, here: https://www.opentable.com/state-of-industry
Historical data on stock market prices was pulled from finance.yahoo.com.
Charts and maps seen in this post were created in R, using the ggplot2 and ggmaps packages.
If you have questions or constructive feedback, feel free to email me at troded24@gmail.com, submit an inquiry on this website, or leave a comment on this post! Thanks for reading - and stay safe.